AlexNet Unveiled: Comprehensive Guide to Its Architecture and Impact
AlexNet, designed by Geoffrey Hinton, winner of the 2012 ImageNet competition, and his student Alex Krizhevsky, represents a breakthrough in the field of deep learning and computer vision. Its debut in the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) marked a significant milestone, as the model achieved a top-5 error rate of 15.3%, outperforming the runner-up by 10.8 percentage points. This performance was made possible by utilizing deep convolutional neural networks (CNNs) and leveraging the power of graphics processing units (GPUs) for computational efficiency during training. AlexNet’s impact did not stop at ImageNet; it paved the way for more advanced architectures such as VGGNet and GoogleLeNet, catalyzing rapid development in the field of deep learning. With an official accuracy of 57.1% in top-1 and 80.2% in top-5 classifications, AlexNet established CNNs as a dominant force in machine learning, particularly in image recognition tasks, and demonstrated the potential of deeper and more complex neural networks to solve traditionally challenging problems.
What is AlexNet?
AlexNet is a pioneering convolutional neural network (CNN) architecture, introduced in 2012 by Alex Krizhevsky, along with Ilya Sutskever and Geoffrey Hinton. This architecture consists of five convolutional layers followed by max-pooling layers and three fully connected layers, employing rectified linear units (ReLU) as activation functions. The network was trained using 60 million parameters and 650,000 neurons, which allowed it to learn complex visual patterns from the large ImageNet dataset. AlexNet's design was innovative in its use of GPUs to handle the enormous computational demands, enabling the model to process massive amounts of data efficiently.
A key aspect of AlexNet's design is the use of grouped convolutions, which allowed the network to split the workload across two GPUs, a novel technique at the time. This architecture demonstrated that the depth of a model plays a crucial role in its performance, as deeper networks could capture more abstract and high-level features from input data. The success of AlexNet in the 2012 ImageNet competition fueled the growth of deep learning, proving the scalability of CNNs for large datasets and leading to widespread adoption of neural networks in computer vision tasks.
AlexNet was more than just an academic success; it transformed the field of deep learning by showing that neural networks, particularly CNNs, could excel in tasks like image classification. Its ability to recognize objects at scale helped establish deep learning as the go-to method for computer vision, with applications spanning from autonomous vehicles to medical imaging and facial recognition. As a result, AlexNet’s architecture and its success in image classification have continued to influence the design of many subsequent neural network models.
Importance of AlexNet
AlexNet holds a pivotal place in the history of deep learning and computer vision due to its groundbreaking contributions, which reshaped how neural networks are applied in real-world tasks. Its importance can be understood through several key factors:
1.Breakthrough Performance: AlexNet achieved a major leap in image classification accuracy during the 2012 ImageNet competition, where it outperformed all previous models. This victory highlighted the immense potential of deep learning algorithms in handling complex image recognition tasks, marking a turning point in the adoption of neural networks for large-scale visual data.
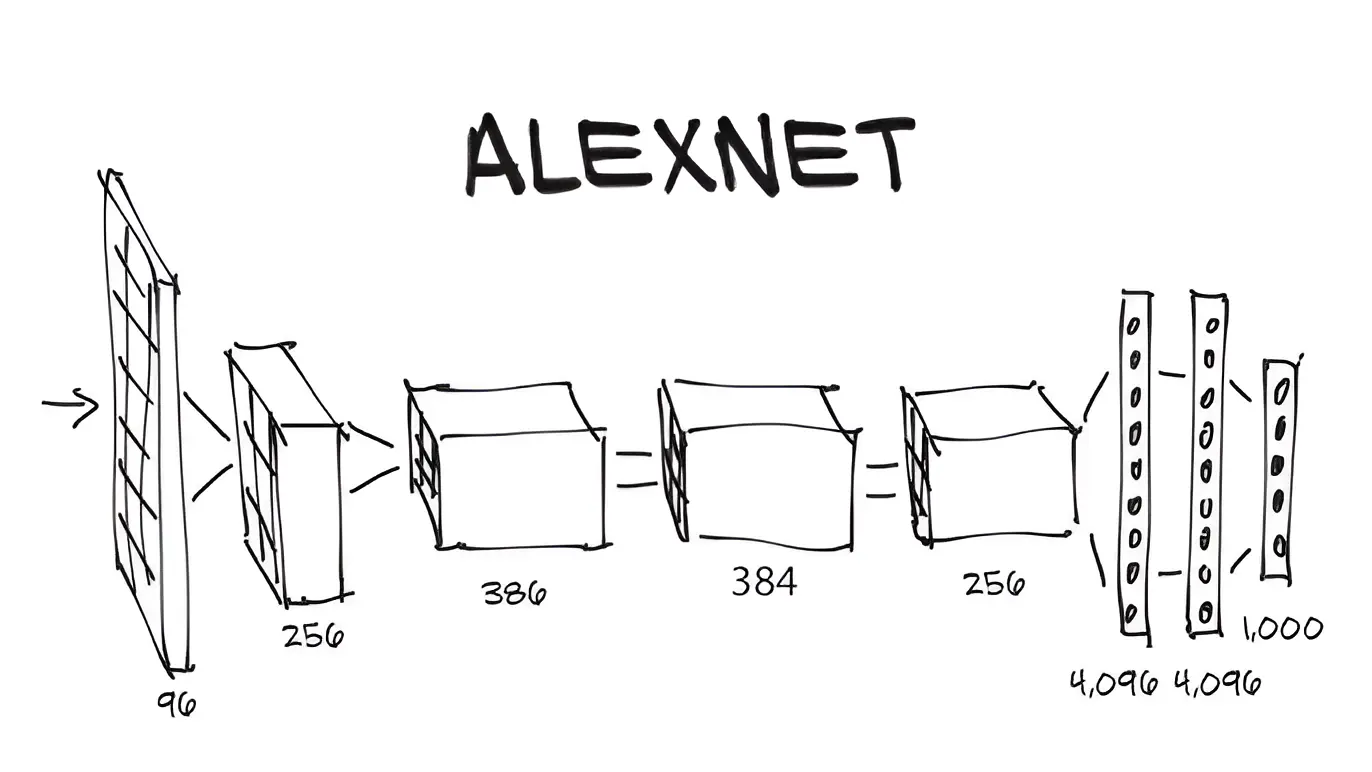
2.Deep Architecture: The network architecture of AlexNet is composed of eight layers, including five convolutional layers and three fully connected layers. This was much deeper than earlier models, and its success underscored the value of using deeper architectures to capture more intricate features from input data. AlexNet’s deep structure helped set a standard for future convolutional neural networks (CNNs), such as VGGNet and ResNet, which would further refine the use of depth in networks.
3.Use of GPUs: One of the most innovative aspects of AlexNet was its use of Graphics Processing Units (GPUs) to accelerate the training process. Before this, training deep networks on large datasets was computationally prohibitive. By leveraging GPUs, AlexNet dramatically reduced training times and unlocked the ability to handle vast amounts of data efficiently, a crucial factor in its success on the ImageNet dataset.
4.Innovative Techniques:
- ReLU Activation: AlexNet employed Rectified Linear Units (ReLU) as its activation function, which allowed for faster and more efficient training compared to traditional activation functions like sigmoid or tanh. ReLU became a cornerstone of deep learning due to its ability to combat the vanishing gradient problem, facilitating the training of deep networks.
- Dropout: Another key innovation in AlexNet was the use of dropout, a regularization technique that randomly drops neurons during training. This helped prevent overfitting by ensuring the model did not become too reliant on specific neurons, improving its generalization to unseen data.
- Data Augmentation: AlexNet enhanced its robustness and ability to generalize through data augmentation techniques such as image translations, reflections, and other transformations. These methods artificially increased the diversity of the training data, making the model more resilient to variations in input images.
5.Large-Scale Data: AlexNet was trained on the massive ImageNet dataset, which contains millions of labeled images across thousands of categories. This demonstrated the importance of using large and diverse datasets in machine learning, showing that neural networks can effectively scale and improve when trained on extensive data. The use of such large-scale data was critical in achieving the model's high performance.
6.Inspiration for Research: AlexNet’s success laid the groundwork for a new era of deep learning research. Its architecture and techniques have been used as a foundation for numerous subsequent models and innovations, such as VGGNet, GoogleLeNet, and ResNet. By proving that deep learning could outperform traditional methods on large datasets, AlexNet spurred further advancements in both neural network architectures and the broader field of artificial intelligence.
AlexNet is not just important for its performance in the ImageNet competition but for revolutionizing the field of deep learning through its deep architecture, innovative techniques, and use of GPUs. It provided a blueprint for future research and application in computer vision, solidifying CNNs as a dominant model for image classification and beyond.
AlexNet Architecture
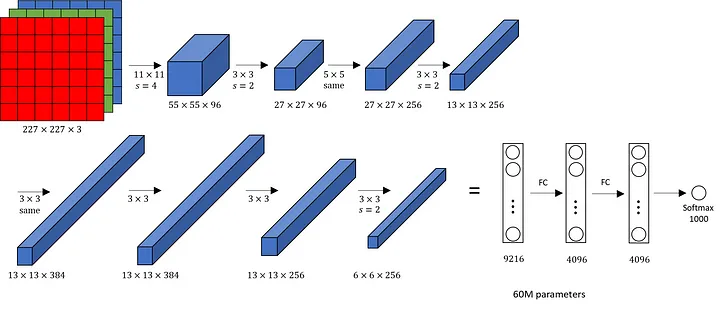
AlexNet was the first convolutional neural network (CNN) architecture to utilize a GPU, significantly boosting training performance and enabling deep learning models to process large datasets efficiently. The architecture consists of five convolutional layers, three max-pooling layers, two normalization layers, two fully connected layers, and one softmax layer. Each convolutional layer features convolution filters paired with a non-linear activation function called ReLU (Rectified Linear Unit). Unlike earlier architectures that used saturating functions like tanh or sigmoid, AlexNet’s use of ReLU allowed for faster training and solved the vanishing gradient problem, making it easier to train deep networks. The pooling layers implement max-pooling, which reduces the spatial dimensions of the feature maps and helps prevent overfitting by providing an abstracted representation of the data. Due to padding adjustments, the input size of AlexNet is 227x227x3, though it is often mentioned as 224x224x3. With over 60 million parameters, AlexNet was able to capture a wide variety of visual features, contributing to its success in image recognition tasks.
AlexNet used a batch size of 128 during training, further improving the efficiency of processing large amounts of data. To optimize the learning process, the model employed Stochastic Gradient Descent (SGD) with momentum. This helped the network converge faster and avoid getting stuck in local minima, which could slow down or hinder learning. AlexNet was trained using data augmentation techniques to prevent overfitting and increase the diversity of its training data. These techniques included image flipping, jittering, random cropping, and color normalization. For instance, the network randomly selected 227x227 crops from 256x256 images, which not only added more variety to the training data but also multiplied the dataset size by 2048, greatly enhancing the model’s ability to generalize.
Training AlexNet required substantial computational resources. The model was trained on a GTX 580 GPU with 3 GB of memory, which could not fit the entire network at once. To address this limitation, the network was split across two GPUs, with half of the neurons and feature maps assigned to each GPU. This parallelization enabled the training of deep networks on large-scale datasets like ImageNet and laid the foundation for the widespread use of GPUs in deep learning.
Max Pooling
Max pooling is a core feature of convolutional neural networks, and AlexNet used it to progressively reduce the spatial dimensions of the feature maps. Pooling helps reduce the number of parameters and computations in the network, making it more efficient. In AlexNet, the authors used overlapping pooling windows sized 3x3 with a stride of 2 between adjacent windows. This overlapping strategy reduced the top-1 error rate by 0.4% and the top-5 error rate by 0.3%, compared to using non-overlapping windows of size 2x2. Max pooling also aids in preventing overfitting by abstracting the learned features, which helps the network generalize better.
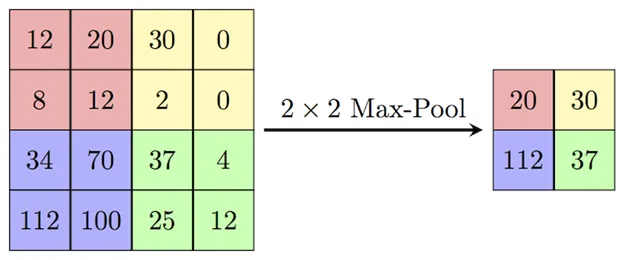
ReLU Non-Linearity
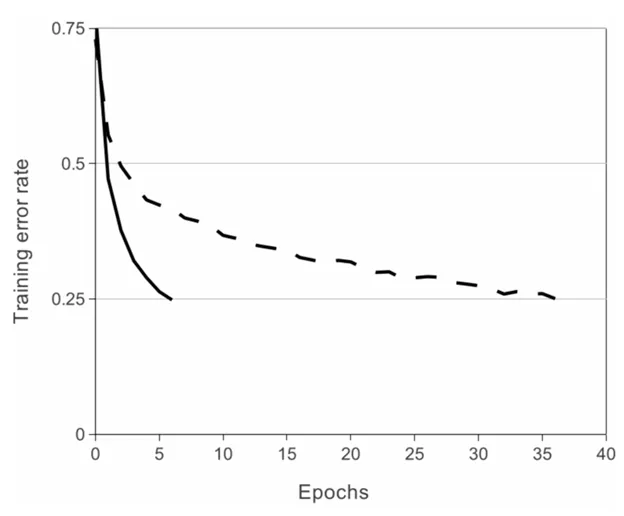
The use of ReLU in AlexNet was a major innovation that accelerated the training of deep networks. Saturating activation functions like tanh or sigmoid often led to slow training because they caused gradients to vanish during backpropagation. In contrast, ReLU allowed the network to learn faster by preventing the vanishing gradient problem. On datasets like CIFAR-10, ReLU helped AlexNet achieve a training error rate of 25% six times faster than networks using tanh activation. This speed improvement was critical in making AlexNet scalable to large datasets like ImageNet.
Data Augmentation
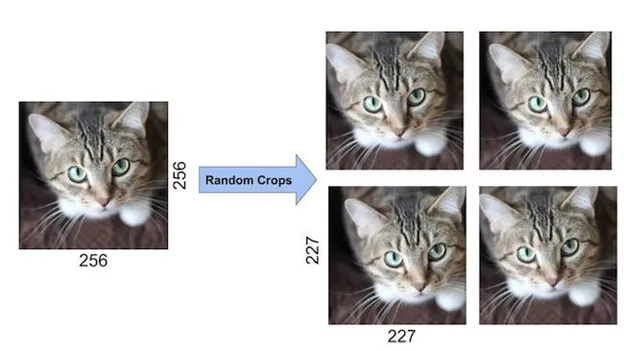
To prevent overfitting and further enhance its generalization capabilities, AlexNet employed data augmentation techniques. One of the primary methods was mirroring, where images were flipped horizontally, effectively doubling the size of the training dataset. For example, flipping an image of a cat across the vertical axis produces a new training example, increasing the model’s exposure to variations in the data. Additionally, AlexNet used random cropping, where 227x227 crops were randomly selected from the original 256x256 images. This technique generated new variations of the original images, further expanding the dataset and ensuring that the model did not overfit to the training data.

Dropout
To combat overfitting, AlexNet used a technique called dropout. During training, neurons were randomly dropped from the network with a probability of 0.5. A dropped neuron did not contribute to forward or backward propagation during that iteration. This forced the network to rely on different subsets of neurons during training, reducing the risk of overfitting and making the model more robust. As a result, the learned weight parameters were more reliable and less prone to overfitting, ensuring better performance on unseen data.
AlexNet’s architecture, with its innovative use of ReLU activation, max pooling, GPU training, dropout, and data augmentation, set a new standard in deep learning. By efficiently training deep networks on large datasets, AlexNet demonstrated the feasibility of using CNNs for complex tasks like image classification and influenced the design of future neural network architectures.
Before AlexNet
Before the development of AlexNet, machine learning models like Support Vector Machines (SVMs) and shallow neural networks dominated the field of computer vision. These models had significant limitations, making it difficult to scale them to more complex tasks or handle larger datasets. Training deep models with millions of parameters, which is now common, seemed nearly impossible. Several key obstacles in earlier models highlight why the breakthrough of AlexNet was so transformative.
Feature Engineering
One of the major limitations of SVMs and shallow neural networks was the reliance on extensive handcrafted feature engineering. These models required manual selection and design of features, which limited their ability to generalize across different tasks. Feature engineering involves selecting the most relevant features from raw data, and while it could work for small, specific tasks, it became impractical for larger datasets and complex patterns like those in images. This manual process severely hindered the scalability of machine learning models, as the models struggled to extract high-level features from data autonomously. In contrast, AlexNet and other deep learning models automated the feature extraction process, learning features directly from the data.
Computational Resources
Prior to AlexNet, computational resources posed a major bottleneck in the training of neural networks. CPUs (central processing units) were the primary hardware available for training models, and they lacked the parallel processing capabilities required for deep learning. The shift occurred when Nvidia released its CUDA API, which allowed AI researchers to harness the power of GPUs (graphics processing units). GPUs enabled the parallel processing of large amounts of data, which was crucial for training deep networks with millions of parameters. This shift in hardware accessibility made it feasible to train deeper, more complex models and marked the beginning of a new era in artificial intelligence. The quote from Alan Kay, "The best way to predict the future is to invent it," perfectly encapsulates how Nvidia's GPU technology changed the trajectory of machine learning, making the future of deep learning possible.
Vanishing Gradient Problem
Another key challenge faced by deep networks before AlexNet was the vanishing gradient problem. This issue occurs when the gradients, used to update model parameters during backpropagation, become exceedingly small or even disappear entirely in deeper layers. When gradients vanish, the network struggles to learn, as updates to the weights become negligible. As a result, neural networks of that era were shallow, limiting their ability to capture complex patterns. The ReLU activation function, used in AlexNet, addressed this issue by preventing the vanishing of gradients, allowing deep networks to learn effectively.
Lack of Large Datasets
Beyond computational limitations and algorithmic challenges, there was also a shortage of large datasets to train on before AlexNet. Machine learning models require vast amounts of data to learn robust features and generalize well to new tasks. Without access to large-scale datasets like ImageNet, earlier models struggled to reach the performance levels needed for more challenging applications in computer vision. As Albert Einstein once said, "Information is not knowledge." The abundance of data, in conjunction with the power of AlexNet's architecture, allowed deep learning to flourish, transforming raw data into actionable knowledge.
The limitations of earlier machine learning models, manual feature engineering, inadequate computational resources, the vanishing gradient problem, and a lack of large datasets created an environment where deep learning seemed out of reach. AlexNet overcame these hurdles, ushering in a new era of scalable, deep neural networks that revolutionized computer vision and set the stage for the AI revolution that followed.
Applications of AlexNet
Although AlexNet was initially developed for image classification, its architecture and the advancement of transfer learning (a technique that repurposes a model trained on one task for a new but related task) have expanded its use across a wide range of fields. AlexNet’s deep convolutional layers form the backbone for many modern object detection models, such as Fast R-CNN and Faster R-CNN, which are utilized in applications like autonomous driving and surveillance. The flexibility of AlexNet's architecture has led to its implementation in several diverse and impactful domains.
Autism Detection
AlexNet has been employed in medical research, particularly in the early detection of autism. Researchers such as Gazal and their team developed a model that applied transfer learning, training an AlexNet model on the large-scale ImageNet dataset and then fine-tuning it on their autism-specific dataset. This approach allowed them to leverage AlexNet’s powerful feature extraction capabilities to identify patterns in medical images that could indicate early signs of autism in children. This application demonstrates how the model's architecture can be adapted to analyze medical data beyond its original design for image classification.

Video Classification
In the field of video classification, AlexNet has been instrumental in extracting key features from video frames, enabling tasks like action recognition and event classification. By utilizing the deep convolutional layers of AlexNet, researchers have been able to analyze temporal and spatial patterns in videos, making it useful for applications such as sports analytics, security surveillance, and even entertainment, where accurate recognition of movements and events is crucial.

Agriculture
In agriculture, AlexNet plays a vital role in monitoring plant health and conditions through image analysis. Farmers use AlexNet-based models to identify early signs of plant stress, diseases, and pest infestations, enabling them to take timely corrective actions. This not only helps in improving crop yield but also ensures better quality produce. Additionally, AlexNet is used in detecting weeds and pests, which is crucial for optimizing resource usage in farming and reducing crop damage.
Disaster Management
In the realm of disaster management, AlexNet is employed to assess damage and aid in emergency response efforts. Using images from satellites and drones, rescue teams can analyze disaster-stricken areas to make informed decisions about where relief efforts should be concentrated. AlexNet’s capability to process vast amounts of image data quickly makes it an invaluable tool in disaster relief, where timely decisions can save lives.
Medical Imaging
AlexNet has also made significant contributions to medical imaging, where it assists in diagnosing various diseases by analyzing X-rays, MRIs, and CT scans. For instance, the model is used in detecting cancers and other critical conditions, particularly in brain MRIs where subtle patterns are crucial for early diagnosis. In addition to diagnosing organ-specific illnesses, AlexNet is used to monitor eye diseases by analyzing retinal images, helping doctors identify conditions such as diabetic retinopathy and glaucoma. Its accuracy and efficiency in processing medical images have made AlexNet a critical tool in modern medical diagnostics.
AlexNet’s applications span far beyond image classification, extending into diverse fields such as healthcare, agriculture, video analysis, and disaster management. Its architectural advances, combined with techniques like transfer learning, have enabled professionals across industries to harness its power for specialized tasks, demonstrating the wide-reaching impact of deep learning models.
Conclusion
AlexNet, with its groundbreaking architecture and innovative techniques, revolutionized the field of deep learning and computer vision. Initially developed for image classification, AlexNet's contributions extend far beyond, powering applications in healthcare, agriculture, disaster management, and more. Its success demonstrated the power of deep neural networks and GPUs in handling large datasets, establishing a foundation for future advancements in artificial intelligence. AlexNet remains a cornerstone in the development of modern deep learning models, influencing both research and practical applications across various industries.
FAQs
Q. What role did GPUs play in the success of AlexNet?
AlexNet utilized Graphics Processing Units (GPUs) to significantly speed up the training process, making it feasible to train deep neural networks on large datasets. GPUs enabled parallel processing, which was essential for handling the computational demands of AlexNet's architecture, and paved the way for their widespread use in deep learning.
Q. How did AlexNet address the vanishing gradient problem?
AlexNet implemented the Rectified Linear Unit (ReLU) as its activation function. ReLU prevented the vanishing gradient problem, which was common in earlier models using sigmoid or tanh functions. By ensuring gradients did not disappear, ReLU helped AlexNet train faster and more efficiently.
Q. How did AlexNet contribute to transfer learning?
AlexNet's architecture became a foundation for transfer learning, where models pre-trained on large datasets like ImageNet are repurposed for new tasks. This technique allowed AlexNet to be adapted for applications such as autism detection, medical imaging, and agriculture, among many others.
© 2024 lamodella.info, Inc. All rights reserved.